KAPITTEL 9 DATAMODELLERING OG NORMALISERING
DEL I. Dataorientert Analyse
Hvordan lage en datamodell
Først så må vi finne ut hvilke "Ting" vi skal registrere informasjon om. Hvilke ting vi skal ha med i Modellen.
Ofte kan det være uklart når vi leser kravspesifikasjonen. Men alltid er et noen tabeller vi vet at vi må ha. Vi begynner da med de, og så vil de andre dukke opp etter hvert. Les kravspesifikasjonen nøye.
La oss si at det er Personer og Biler:
RELASJONER
Det kan være gunstig å trekke relasjonene. Ofte vil man da se at det er bruk for flere tabeller.
Det er fire relasjoner vi må definere. To maksimum, og to minimum.
a) Maksimumsrelasjonene
Hvor mange biler kan en person eie (Maksimalt): Jo; flere.
Hvor mange eiere kan en bil ha (Makimalt); Jo; en.
Vi får da en datamodell som ser ut som følger:

På VKI såg vi kun på Maksimumsrelasjoner. De er også de viktigste.
Vi skal alltid få en en-til – mange relasjon. Unntaket er selvsagt en Mange til mange relasjon slik som dette:

En bok kan lånes av (maksimum) flere kunder.
En kunde kan låne (maksium) flere bøker.
I dette tilfellet må vi spalte opp relasjonen slik at vi ender opp med to en –til –mange relasjoner. Som vi husker kaller vi det å Entitetisere. Det gjøres ved å legge inn en mellomtabell. Denne tabellen bygger bro mellom Kunder og Bøker.
Så: vi ender alltid opp med En-til-mange-relasjoner.
b) Minimumsrelasjoner
Disse er mindre viktige, men vi fyller de alltid ut.
Nesten alltid er det snakk om en eller null.
En Bil må eies av (minimum) en person
En person må eie (minimum) null biler. (Dvs vi kan legge inn en person i databasen, en kunde, uten at vi selger en bil til denne)
Fyll alltid ut Modellen slik i Modellator. Dvs null til en. Det er kun eksperter som en sjelden gang kan ha interesse av å sette opp andre minimumsbetingelser.
Modellen vil da se slik ut:

Vi setter minimumsrelasjonene innerst.
Husk på å skrive inn forklaring i modellen. Det gjøres i relasjonsvinduet i Modellator.
LEGGE INN ATTRIBUTTER(EGENSKAPER) I MODELLEN
Prinsipper
Når vi har funnet ut at vi skal ha to tabeller, Personer og Biler, vil neste trinn være å bestemme hvilken type informasjon vi skal registrere for personer, og for biler.
Det fine med datamodellering er at gjennom å gjøre dette vil vi oppdage at vi må ha andre entiteter (tabeller) i modellen. Man begynner altså i det små, med to tabeller, etter hvert som de blir til vil vi se at andre tabeller er nødvendige.
Eksempel: Om person skal vi registrere Postnummer og poststed. Vi ser da at vi kan skille ut disse to atributtene i en egen entitet(tabell). Det er fordi de hører sammen. På den måten ungår vi dobbeltlagring. Vi registrerer kun Postnummer i Persontabellen, som slår opp poststed.
Vi har også sett at gjennom å trekke relasjonen mellom Person og Bøker så oppdaget vi at vi trengte en mellomtabell for å spalte opp Mange til mange relasjonen. Mellomtabellen vil da registrere utlån.
Det å skille ut attributter(egenskaper) til nye entiteter(tabeller) kalles for NORMALISERING.
Hvis vi oppdager at noen felt i en entitet(tabell) Beskriver noe annet (en annen ting en det tabellen skal beskrive) så kan disse feltene ofte skilles ut som en egen entitet. Og relateres til Den Opprinnelige.
Eksempel:
Vi lager en tabell for ansatte. For hver ansatt skal vi registrere avdelingsnummer,
avdelingsnavn, avdelingsleder, og avdelingsplassering (i Bygningen). Disse fire
attributtene beskriver da en separat ting. Nemlig en avdeling. De kan da skilles ut som en
egen entitet og relateres til Ansatttabellen. ( Vi ser da at vi for hver ansatt ikke
trenger å registrere all avdelingsinformasjon. Opp igjen og opp igjen. Det er nok å
skrive inn avdelingsnummer som så henter nødvendig data fra avdelingstabell.)
(Det samme gjelder for Postnummer og poststed. Disse to attributtene beskriver en separat ting: Postadresse.)

I stedet for å gjøre det slik, skiller vi ut to entiteter på denne måten og lager relasjonene:


Legg merke til sekundærnøklene i ansatt-tabellen.
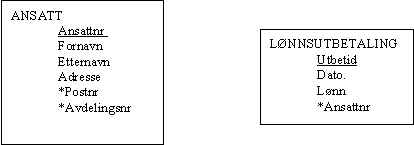
Eksempel: Vi skal registrere lønnsutbetalinger for hver ansatt.
Hvordan gjør vi det? . Vi kan tenke oss at det er en egenskap ved en ansatt. Slik at vi tilføyer et felt kalt Lønnsutbetaling . På denne måten.

Men vi kommer da på at En ansatt har flere utbetalinger. En hver måned. Vi kan da ikke lage et felt i Ansatttabellen for hver måned. Det blir en stor og uoversiktlig tabell. Det enkleste er å skille ut en egen tabell. Kalt for lønnsutbetaling. Slik:
*********
HODE-LINJESTRUKTUR: OPPSPLITTING AV EN ENTITETISERING
Dette er en meget vanlig struktur å få til eksamen. Så derfor må dere kunne den godt.
Vi illustrerer den ved hjelp av et eksempel:
ORDRESYSTEM
En bedrift selger varer til kunder. Kundene er butikker.
Dette betyr at vi må ha en Kundetabell, med informasjon om hver enkelt kunde. (Det er altså ikke kontantsalg). I kundetabellen finner vi all informasjon vi trenger for å sende regninger og reklame til kundene.
Vi får da denne datamodellen:

Hvilken Relasjon har vi mellom varer og kunder?
Jo: En vare(type) kan kjøpes av mange kunder. Og en kunde kan kjøpe mange varer.
Vi har en mange til mange relasjon og må entitetisere.
Vi får da en mellomtabell. Mellomtabellen kobler Varer og kunder. En kobling mellom varer og kunder må være et Kjøp. Kunder kjøper varer. Relasjonen mellom kunder og varer er Kjøp.
Mellomtabellen kan vi derfor kalle for ordrer.

La oss se på relasjonene
I. En kunde kan levere flere ordrer (gjøre flere kjøp). Et kjøp angår kun en kunde. (Selv om flere kunder betaler så registreres det kun på en kunde.) Så vi får en en – til mange relasjon her.
II. En ordre(Et kjøp) kan inneholde flere varer. Og en vare kan finnes for mange ordrer (kan kjøpes mange ganger). Mange til mange relasjon.
Så vi blir ikke kvitt mange til mange-relasjonen. Vi må entitetisere ytterligere. Og får det som kalles HODE-LINJE-STRUKTUREN.
Etter en ytterligere Oppsplitting vil vi få denne modellen:
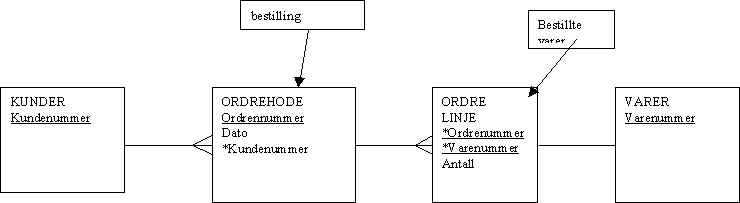
Ordrehode tar for seg Dato og ordrenummer. Ordren identifiseres ved kundenummer.
I ordrelinje vil vi Koble Ordre og Vare. Dvs Vi får Alle varer for en Ordre (et kjøp).
Hver post i tabellen Ordrelinje vil da bli en linje i Ordren (bestillingen). På linja vil det stå Ordrenummer, varenummer og antall av varen.
Relasjonene:
En ordre(ordrehode) kan inneholde mange varelinjer(bestillte varer)
En vare kan bestilles mange ganger (kan finnes for mange ordrelinjer)
DEL II. NORMALISERING
Normalisering går på at man foretar en tilfredsstillende entitetisering,, dvs oppsplitting i Entiteter.
Dette for å unngå dobbeltlagring av informasjon.
Dobbeltlagring har flere ulemper:
*Unødvendig lang tid
*Tar stor lagringsplass
*Databasen går sakte
*Vanskelig å oppdatere siden en type data finnes flere steder
*Inkonsistens i data; hvis man glemmer å oppdatere dataene et sted
Innenfor databasekonstruksjon snakker man om ulike PROBLEMER som kan løses gjennom OPPSPLITTING.
Man kaller de for PROBLEMTYPE 1, 2 OG 3.
LØSNINGENE på disse problemene er å NORMALISERE. Vi snakker om løsninger på 1., 2. Og 3. Normalform. (Første, andre og tredje grads Normalisering)
Vi skal illustrere disse PROBLEMENE og løsningene ved hjelp av eksempler:
PROBLEMTYPE 1: Gjentakelse av et felt i en entitet (Problemer på første normalform)
NOEN GANGER SER VI AT EN ATTRIBUTT MÅ GJENTAS MANGE GANGER FOR EN PERSON.
EN ANSATT VIL FOR EKSEMPEL HA EN LØNNSUTBETALING HVER MÅNED. OG ALLE DISSE SKAL REGISTRERES.
DET KAN VI GJØRE SLIK:

PROBLEMER MED DENNE LØSNINGEN
VI MÅ LAGE VELDIG MANGE FELT I DENNE ENTITETEN
DET BLIR PROBLEMER MED SPØRRINGER. FX: Å FÅ UT LØNN FOR EN PERIODE.
EN BEDRE LØSNING:
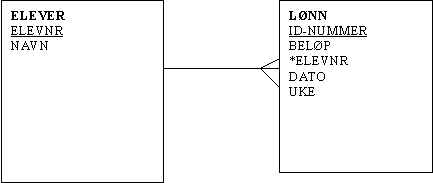
VI SKILLER HER UT LØNN SOM EN EGEN ENTITET OG KOBLER OPP.
FORDELER:
VI TRENGER IKKE LAGE NYE FELT
SPØRRINGER BLIR ENKLERE
MER OVERSIKTLIG
PROBLEMER MED 3. NORMALFORM
ET SETT AV ATTRIBUTTER INNENFOR EN ENTITET BESKRIVER NOE ANNET
EKSEMPEL:
EN ANSATT JOBBER I EN AVDELING. VI SKAL DA REGISTRERE AVDELINGSINFORMASJON OM DENNE ANSATTE.
DET KAN GJØRES SLIK:
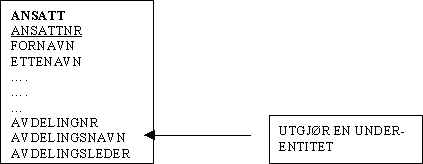
PROBLEMER:
AVDELINGSINFORMASJON BLIR REGISRERT IGJEN OG IGJEN FOR ALLE ANSATTE. TAR OPP MYE LAGRINGSPLASS.
LØSNING:
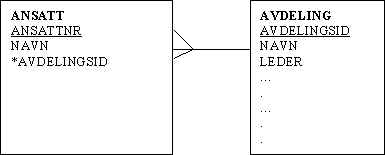
FORDELER:
VI SPARER LAGRINGSPLASS: AVDELINGSINFO BLIR REGISTRERT EN GANG I SIN EGEN ENTITET. AVDELINGSID I ANSATTTABELLEN BRUKES TIL Å SLÅ OPP NØDVENDIG INFORMASJON.
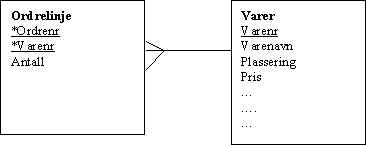
PROBLEMER MED 2. NORMALFORM
Dette problemet oppstår bare hvis vi har en identifikator som består av to attributter
EX.

Problemer:
Vi må skrive samme varenavn mange ganger: Dobbeltlagring: tar opp stor plass.
Vi har ingen tabell der vi kan registrere varer på lager, og vareinformasjon som pris og plassering. Hvis en ordre blir slettet blir også varen slettet og vi vet ikke om vi har den på lager.
Løsning: Skill ut Varer som en egen entitet: